Article
Turn documents into data
Introduction
Sounds familiar? Many organizations rely on data arriving in various shapes and sizes—emailed attachments, portal uploads, or physical documents requiring manual handling. We’ve written about this before here. Conventional methods involve a meticulous dance: documents are received or downloaded, saved somewhere centrally, opened and reviewed, often one by one. Crucial information is painstakingly copied and pasted into spreadsheets or directly into applications, a time-consuming task prone to errors.
The trouble doesn’t stop there. Reviewing this copied data is a daunting task as it exists in silos—partly residing within the original document and partly within the target system. This fragementation makes conducting a comprehensive 'four eyes' review difficult. Reducing the accuracy and efficiency of the process.
The original document and its captured data lose their connection along the journey, leading to potential discrepancies, data mismatches, and an overall lack of synchronization between the source and the processed information.
The need for a better solution is more than evident, Mesoica gets rid of these cumbersome and error-prone manual processes.
We've described the typical steps in an IPD workflow before, here’s a refresher:

In this article we dive into the ’Capture’ step, explaining what kind of data users typically extract from documents and how this is achieved efficiently using the Mesoica platform.
The solution: turn documents into data
Intelligent Document Processing (IDP) is a must to achieve efficiency for any company dealing with documents on a regular basis and aiming to streamline the entire process. Leveraging a fusion of cutting-edge technologies including Optical Character Recognition (OCR), Natural Language Processing (NLP), and Machine Learning (ML); Mesoica's solution sports automated text extraction from diverse document formats.
Automated text extraction
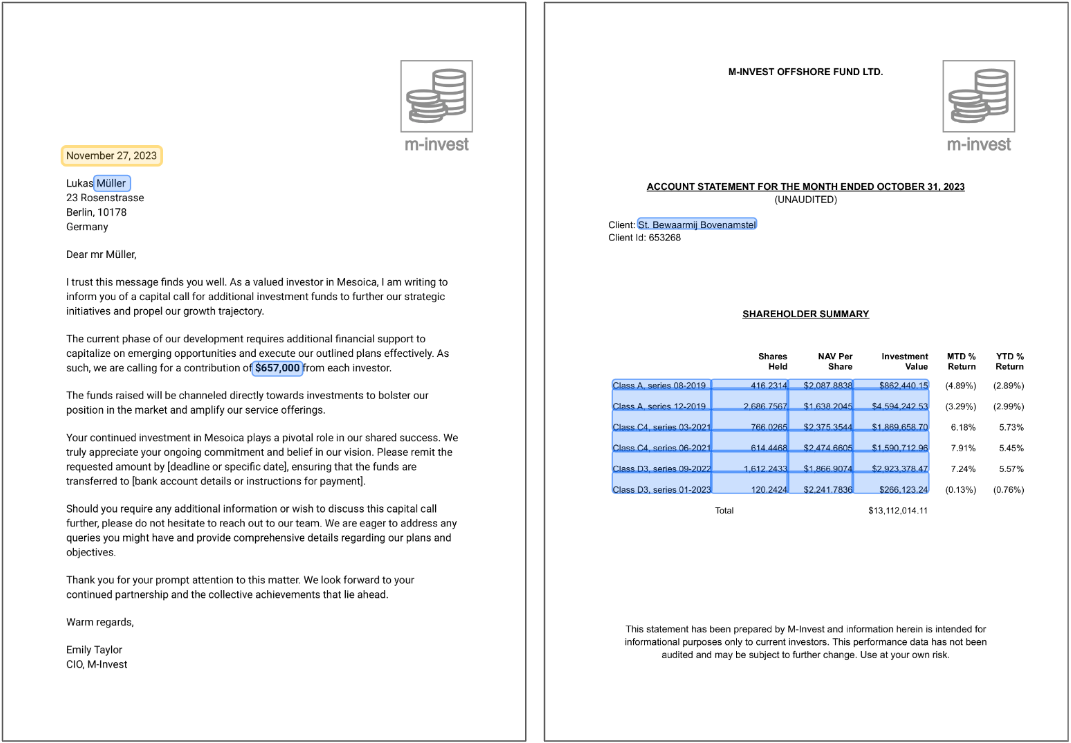
One of the pillars of our IDP solution lies in its automated text extraction capabilities. Through the use of simple configuration and LLMs, IDP can reliably extract textual data from documents, freeing it from the confines of PDFs, images, emails, or other formats. This significantly slashes the time spent on manual data entry, eliminating errors and discrepancies that often plague manual transcription.
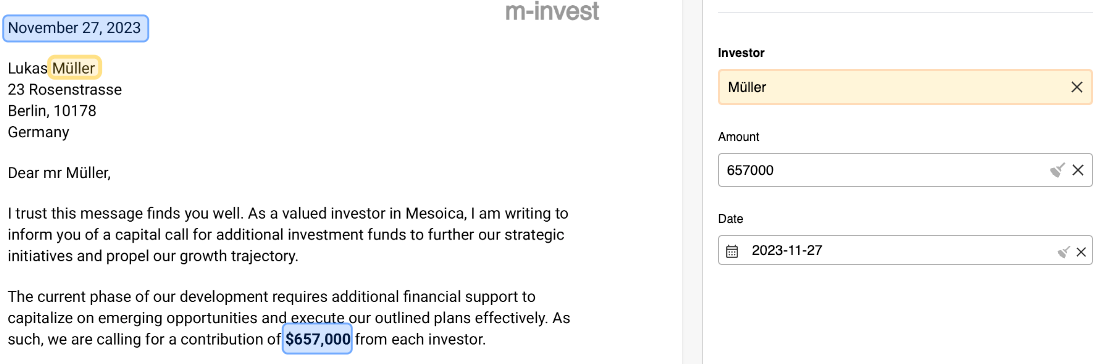
Table extraction
An area where massive improvements can be made quickly is table extraction. Tables typically contain a lot of data, sometimes spread out over multiple pages makes for extremely painful transcribing rows and columns. Being able to to pull this out in one go and reshaping it for downstream processing is a game changer.
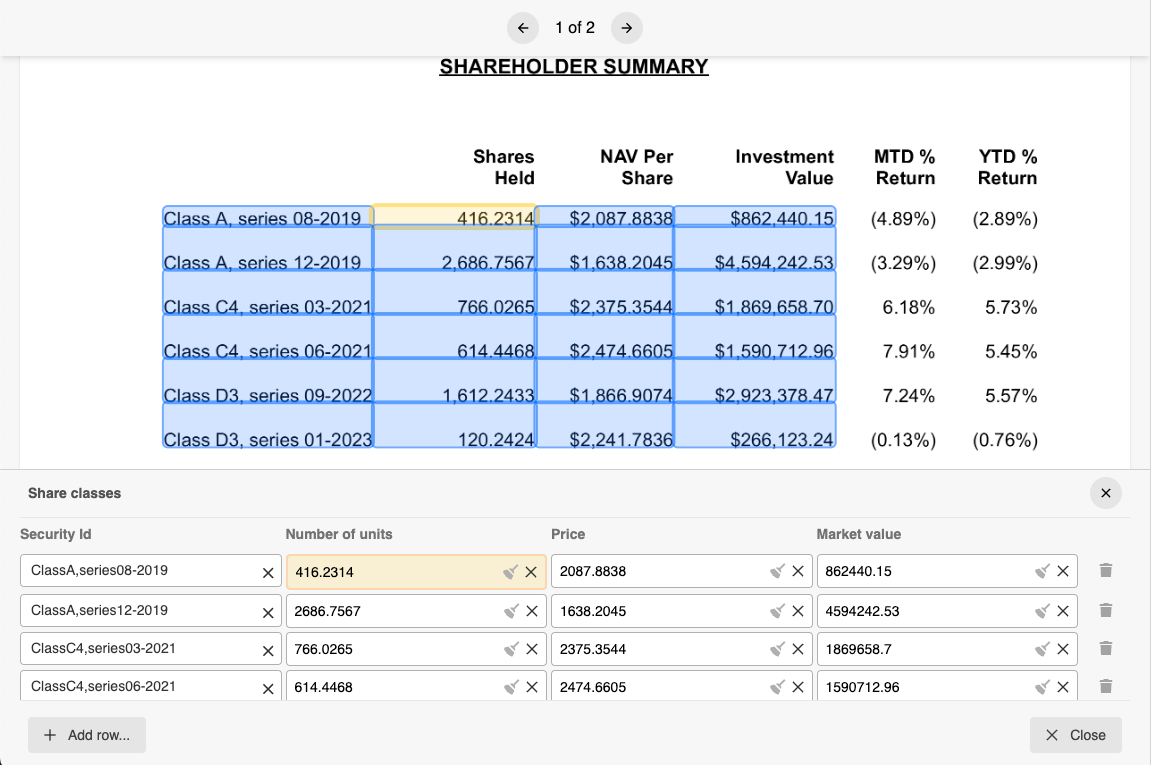
Data matching
Extracted data often does not exactly match business identifiers or entities. For example a client name has different ways of spelling it, or contains certain pre- or postfixes (e.g. Inc. B.V. in various variations). Simply passing these values on to an import process would cause all kinds of trouble down the road. To avoid this the content matching process makes sure extracted data is correlated with business entities within a confidence interval. This not only streamlines data validation but also ensures a comprehensive 'four eyes' review, enhancing accuracy and reliability.

These capabilities combined make for a seamless data flow from documents to databases with precision and speed.
Conclusion
At its core, Mesoica is a drastically improved way to organize manual document based data entry processes:
- By automating the extraction and integration of data, the laborious and error-prone task of manual entry is a thing of the past. This saves time ánd frees up valuable human resources to focus on more strategic and value-added tasks.
- Automation and accuracy of data extraction, coupled with matching algorithms, drastically reduce the number of data entry errors. This translates into higher data quality and more reliable downstream databases, fostering trust in the integrity of information.
- A systematic approach to document processing makes for a robust and automated audit trail. Every step, from data extraction to integration, is automatically logged, providing a comprehensive trail of actions. This not only ensures compliance but also delivers a transparent and traceable record of data handling.
By eliminating manual entry bottlenecks, businesses no longer discover data discrepancies later in the process. The extracted information seamlessly aligns with the target systems, eradicating the need for post hoc corrections and rework. “First time right” processing!
Mesoica’s data quality platform is specifically designed to help LPs and GPs manage their data efficiently. By using our platform, you can seamlessly collect, validate, and monitor data, enhancing communication and collaboration. Our scalable solution adapts to your organization's growing data needs, providing peace of mind and enabling you to become a truly data-driven organization. Start your journey today by visiting our website or contacting us to learn more about how Mesoica can empower your firm to continuously improve data quality.