Article
First time right: perfect document data quality
Introduction
Understanding the level of data quality of data extracted from documents is critical in avoiding errors and rework downstream. As we described in our previous installment on Intelligent Document Processing (IDP) extracting data can be automated and made into an efficient streamlined process.
Today these processes often involve manual extraction. Typically data is extracted into Excel spreadsheets or operational systems, relying heavily on human effort. Strategies to get to grips with data quality typically are:
- Eyeballing
- Excel macros
- Reconciliation
Relying on 2 or 4 eyes to validate data is not sufficient to guarantee solid data quality. Too often small mistakes fall through the cracks.
Macros can automate data validation to a certain degree. There is still a human element involved opening file and pushing buttons. Although better than doing nothing or eyeballing there is huge opportunity for mistakes due to the manual nature of the check or misconfigured Excel sheets.
Reconciliation is a pretty solid check but inherently inefficient because it can only be done at the end of the process and after all required data has been received. If mismatches are found during this process it can be very time consuming to pinpoint the exact root cause of the problem.
The Mesoica platform makes validation an integral part in the complete document processing workflow. We've described the steps in the IPD workflowbefore, here’s a refresher:

In this article we dive into the ’Validate’ step, explaining the Mesoica platform supports users in fully automating data quality checks and ensuring correct data to downstream systems and processes.
Improving data validation
As we showed previously [LINK]( to doc ) data can be easily extracted from documents into a structured set of fields.
The Mesoica platform makes it a breeze to apply data quality checks on these data points. The steps required are:
- Select rules to apply against a document
- On data extraction run these rules
- Get notified of issues, inspect and fix
Select rules
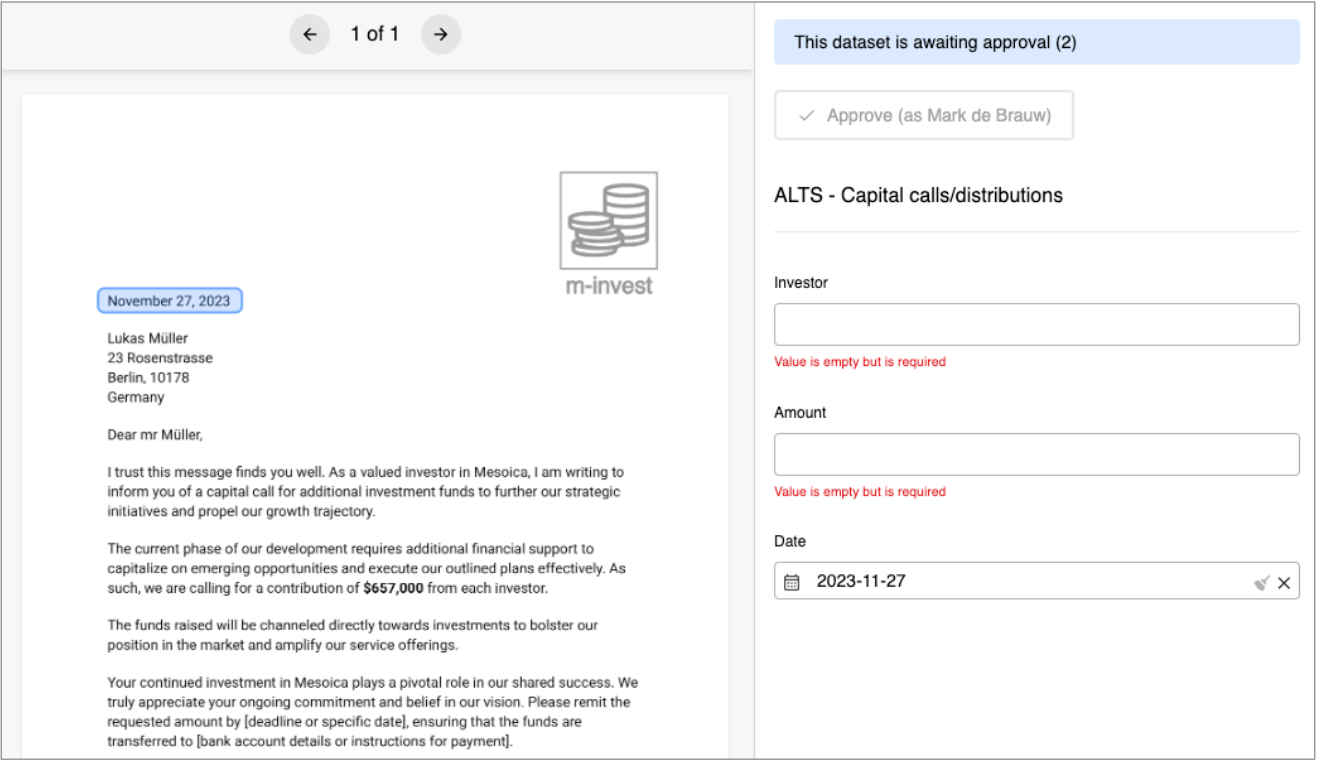
For each type of document, users have the option to select a set of rules. To simplify the process, Mesoica provides a comprehensive library of rules that users can choose from. These rules cover a wide range of scenarios and ensure that users have the flexibility to customize workflows according to their specific requirements.
Run rules
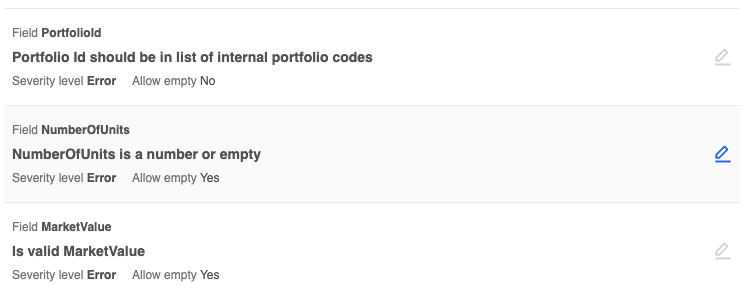
Once the rules are selected and applied, they will automatically be applied to every new document that is uploaded to the platform. This ensures that the selected rules are consistently enforced and that all documents go through the same process of evaluation and analysis. By implementing this automated system, the platform can streamline its operations, improve efficiency, and maintain a high level of quality control.
Review and fix issues
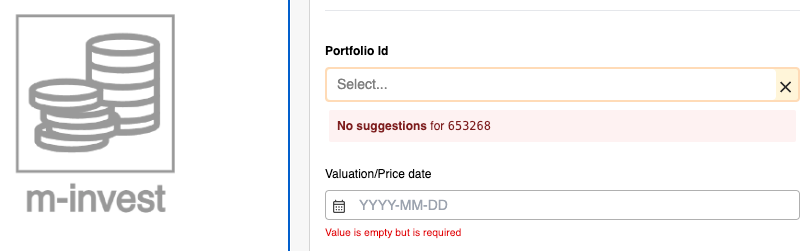
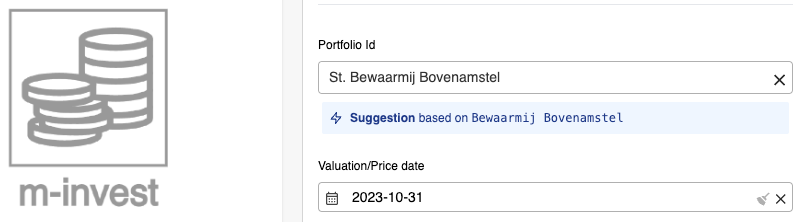
If the extraction process missed something or if an extracted value cannot be correlated to entities in the system, the user has the flexibility to easily override values and make necessary changes to the data. This provides a seamless way for users to ensure data accuracy and integrity within the document processing workflow. Whether it's a minor discrepancy or a more significant mismatch, the user can take control and manually adjust the extracted values as needed. By allowing this level of flexibility, the Mesoica platform empowers users to maintain data consistency and reliability, even in complex scenarios. So, no matter the complexity of the document or the intricacies of the data, the user can confidently rely on the platform's user-friendly interface to review, modify, and validate the extracted values.
Conclusion
Automated document data validation offers numerous benefits, primarily to be able to identify errors at a very early stage. This proactive approach prevents minor inaccuracies from developing into larger, more complex issues. The early detection mechanism not only improves data integrity but also reduces the need for time-consuming post-hoc checks or extensive reconciliation processes.
Furthermore, the push for increased automation makes everything much more efficient. Consider a scenario where, after receiving validation approval, an automated sign-off and export process automatically commence. This shift introduces operational flexibility, where error-free data flow through the organization, reducing the need for human intervention and maximizing efficiency.
In short, integrating early error detection, eliminating after-the-fact reconciliation, and embracing increased automation represent a large leap towards improving both data integrity and operational efficiency.
Mesoica’s data quality platform is specifically designed to help LPs and GPs manage their data efficiently. By using our platform, you can seamlessly collect, validate, and monitor data, enhancing communication and collaboration. Our scalable solution adapts to your organization's growing data needs, providing peace of mind and enabling you to become a truly data-driven organization. Start your journey today by visiting our website or contacting us to learn more about how Mesoica can empower your firm to continuously improve data quality.