Article
Small data, big problems
Companies waste a tremendous amount of time on data preparation. Studies Crowdflower estimate that this can sometimes consume up to 60% of people's time, disguising itself as a regular part of the job. This is a significant problem!
"Small data" can disrupt data-intensive processes and increase the amount of manual data preparation required. To us, small data refers to ad-hoc, manually exchanged, low-volume, and high-value data. Examples of small data include financial statements, capital calls, real estate deals, contracts, financial valuations, etc. all required as input into operational systems, data warehouses, or other downstream applications.
In other words, non-automated data processes can become very disorganized because of the data containers and structure that must be dealt with. These containers include files, documents, and images that contain data that must be extracted, structured, and processed.
Impact of small data
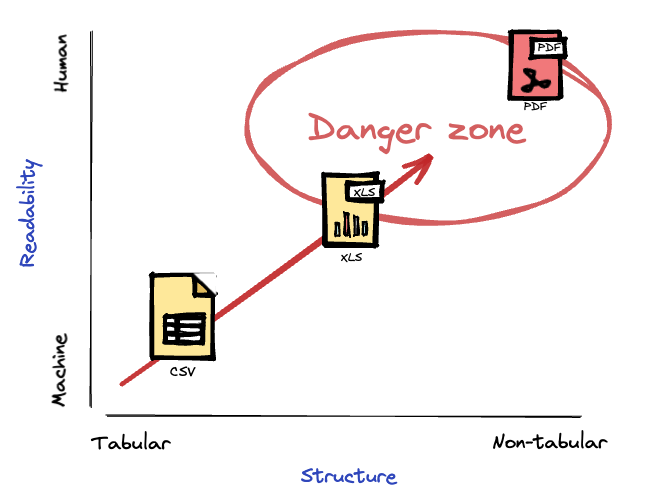
In order to understand the impact of small data containers on data-intensive processes, it is important to consider the structure of the data and its readability by both machines and humans.
When considering data structure, it is important to determine whether it is tabular or organized differently. Tabular data is often easier to read and process, whereas differently organized data can create more complex processes and require more manual data preparation. Examples of differently structured data include financial statements, confirmations, emails, hierarchical and/or aggregated data.
In addition, data readability plays a crucial role in determining the efficiency of data-intensive processes. Data that is easily readable by both machines and humans can be processed and analyzed quickly, reducing the amount of time required for manual data preparation. A financial statement presented in XBRL format can be easily parsed by a machine, but not by a human. Conversely, the same statement presented in PDF is difficult for a machine to parse.
Data that is difficult for machines to read, and contains non-tabular data, often has the greatest impact on operational processes:
Small data categories
The most common data containers used to exchange and process data are Excel sheets, PDFs, CSV documents and JSON/XML files
Excel sheets are readable by both humans and machines. However, a lot of manual intervention is often required due to the following issues:
- Consistency issues can easily creep in due to Excel sheets being the result of a manual reporting process. Column names can change and header rows can be moved around on a regular basis.
- Metadata sections and/or user-provided commentary can provide important clues about the data in the document. For example, a commentary field in a data collection Excel informing the recipient of data that all numbers are in USD can be important, even though numbers can be parsed automatically.
- Data may be located on different tabs and needs to be consolidated.
- Regional settings can be difficult to deal with when exchanging Excel data in an international context.
- Unpacking pivoted data or transposing requires manual steps.
PDFs are easy for humans to read, but difficult for machines to read. This is due to:
- Limited structure and visual-only cues, making it challenging to extract the right data.
- Data is presented in ways that prioritize human experience, such as summaries, hierarchical layout, headers, and roll-ups. These factors increase the amount of manual intervention necessary to extract data from these documents.
Structured tabular data in PDFs is hard to extract manually though, for example copy/paste, manual actions. These kind of containers suffer from the same problems mentioned under the previous bullet.
CSV-like data is well-structured and suitable for automated processes. Ironically, in manual data preparation processes (often Excel-based), CSV can actually cause more trouble:
- Quoting and separator characters usually require some Excel wrangling, such as converting to columns or removing characters, before getting the data into the desired shape.
- Regional settings can be painful when dealing with Excel or even CSV in an international context.
XML and JSON are primarily meant for use in automated processes and consumption by software systems. In our opinion, they have no place in an end-user environment.
Conclusion
We find that small data, as defined by us, is a common phenomenon in many organizations and can have major impact on efficiency, scalability and quality of data operations. However, a structured approach to dealing with it is not widespread. Typical approaches involve using Excel macros or custom Python scripts. Often, there is no focussed approach to breaking out collection, validation, transformation, and delivery into discrete steps that can be optimized, improved, and automated.
How does your organisation deal with small data in a structured manner? We’d be very interested to learn, let us know in the comments.
Mesoica’s data quality platform is specifically designed to help LPs and GPs manage their data efficiently. By using our platform, you can seamlessly collect, validate, and monitor data, enhancing communication and collaboration. Our scalable solution adapts to your organization's growing data needs, providing peace of mind and enabling you to become a truly data-driven organization. Start your journey today by visiting our website or contacting us to learn more about how Mesoica can empower your firm to continuously improve data quality.